開発言語・Haskell
ようこそ、「開発言語」シリーズへ。この連載記事ではプログラミング言語のソフト開発 への適性を議論しています。前編はこちら:
今回は Haskell についてです。
ちょっと待った、Haskellって複雑すぎて天才しか使えないあれだろ
とんでもありません! Haskell は世界中でさまざまな開発者に使われています。コード 自体は綺麗で素早く、ライブラリの数は数万にも及びます。しかもコンカレンシーの仕組 みは上級で、保守やリファクタリングは多くの言語より容易いです。
下記の項には特に順番がありません。目次で内容を自由に飛び回ってください。
Haskellとソフト開発
プログラミング
新しいプロジェクトはどう立ち上げる?コンパイルの仕方は?
プロジェクト管理の主な二つが Cabal と Stack です。使い方には若干異なる部分があり ますが、中身を共有しているところもあり、依存性管理とコンパイルの調整する役割が同じです。
普段なら Cabal は直接 Hackage から依存性を引き下ろします。Hackageとは全てのライ ブラリが載せられるサービスです。一方、Stackは Stackage のパッケージ・セットによっ て依存性のバージョンを決めます。セットに指定されるライブラリは必ずコンパイルし合 い、いわゆる「依存地獄」は免れます。実は最終的にStackageでもライブラリは Hackage から取られる事になります。
さて、どちらにするかとなると… 実は場合によります。
- Hackageとそのまま繋げ、最新の依存性を中心にソフトが作りたい?ならCabal。
- パッケージ・セットの安全性に頼ってソフトが作りたい?ならStack。
どちらでも気にしない、という時は勝手に決めても問題ありません。CabalでもStackでも 保守されていますしユーザーが多いです。本記事では stack の例を出します。
新しいプロジェクトを立ち上げるには:
stack new <プロジェクト名> simple
すると、こういうファイルが作られます:
. ├── foobar.cabal ├── LICENSE ├── README.md ├── Setup.hs ├── src │ └── Main.hs └── stack.yaml
stack build によってコンパイル、 stack test によって検証、 それかそのまま履行す る時は stack run 。いずれかに --fast も加えればオプティマイズなく実行されます。
言語とのやりとりはどんな感じ?
幸い 正式なLSP が提供されています。 ghcup によるインストールが最も分かりやすい:
ghcup install hls
エディタでHaskellファイルを開けばLSPが勝手に作動して期待通りに働いてくれます。
LSPの付け加えとして、予備の端末で ghcid という型チェックのループを開くと便利です。コンパイルをせずに コードの間違った箇所がすぐ分かってきます:
server/Main.hs:(62,10)-(64,41): warning: [-Wincomplete-patterns]
Pattern match(es) are non-exhaustive
In a case alternative: Patterns not matched: English
|
62 | ps = case l of
| ^^^^^^^^^...動的型付けの言語の方ではMVPを立ち上げるのが早いと言われますが、強い静的型付けの Haskellはこの面では決して負けません。返って「型に導かれて」その工程がより効率的 となります。型と関数が契約のような物になります:
-- この型の定義はこれでまだ完成していないかもしれないけれど、
-- とにかく `name` と呼ぶ `String`が必要。
data Person = Person { name :: String }
-- `Family`にはまだ何を入れるか全く決めてなくて今のところ空とする。
data Family
-- 名前を入力として`Person`を(どこか決めてないところから)出そうとする。
person :: String -> IO (Maybe Person)
person = undefined
-- `Person`さえあれば`Family`も出せる。
-- その「どうやって」はまだどうでもいい。
family :: Person -> IO Family
family = undefined
-- 副作用なしに`Family`から`Graph`を作る。
relations :: Family -> Graph Person
relations = undefinedこうやって詳細を確定せずにプログラムの「外側」を設計していくのがよくあります。型 や関数を自由に変える事ができて、プログラムのおおよその形が決まればその中身を埋め るのはまるで雑用にすぎません。
Haskellの機能は?
まずHaskellは強い静的型付けの言語で、ランタイムに管理されるガベージコレクション を行います。
他所の言語ではあまり見ない原則に基づいているお陰、Haskellを体験すると世界が広が ります。その原則とは:
- イミュータブル性 (英: Immutability)
- 遅延評価 (英: Lazy Evaluation)
- 純粋関数 (英: Pure Functions)
この三つ揃って特別な環境が生まれてきます。説明しましょう。まず:
変数の中身が決して変わらない
RustやScalaの「任意ミュータブル性」と違い、Haskellでは変数を変える事が単に不可能。 ましてループも存在しないお陰で普段の「ループしながら配列の中身を自由自在に変えて いく」という多くの問題の解法には頼れません。幸いループを不要にする機能はちゃんと 用意されており、慣れるとループが使いたい気持ちがすっかりと消えていきます。
では次に:
関数の結果は全て”遅延”される
必要になった時まで返り値は実行されません。これでデータ構造や再帰への影響が深い:
これが全てのフィボナッチ数を持つリストです。長さはもちろん無限!しかしリストであ る事に変わりなくいつものリスト関数が使えます:
> take 10 fibs [0,1,1,2,3,5,8,13,21,34] > fibs !! 100 354224848179261915075
sum や length を試みない限り問題ありませんが…
そして最後に:
副作用の有無は型で表す
即ち関数が純粋かどうかは見て分かる事です。
-- | この関数は決してIOができない。
add2 :: Int -> Int
add2 n = n + 2
-- | ここはできる!
addThenPrint :: Int -> IO ()
addThenPrint n = do
let m = add2 n
print madd2 には副作用はありません。しかも関数の内容を確認せずに保証できる事です。型を 見ただけで副作用がない事がすぐ分かります: Int -> Int 。入力も出力もただの Int 。一方、 addThenPrint では IO ができ、その事が型から明白です。もちろん IO 以外に 色々と副作用と呼べるのがありますが実質 IO が主です。
なぜここまで副作用に拘るかというと、まず自分のためになるからです。コードが簡潔な 程、テストしやすいし保守も楽になります。しかもコンパイラも感謝してくれる:副作用 のない関数はインラインしやすくなります。
その他、Haskellは現代的言語であるため便利が多い:
- 業界上級の構造体
- パターンマッチ (英:Pattern Matching)
- Typeclassesとその自動的
deriving
などなど。いわゆる Monads もありますが、それとその周りの機能は副作用のあるコード を繋げるためのものにすぎません。
最後に Haskell 以外の言語に殆ど見つからない特別な機能を紹介します:「穴埋め」 (英:hole fits)。魔法の _ を入れれば…
Landing.hs:78:18: error:
• Found type wildcard ‘_’ standing for ‘Int’
To use the inferred type, enable PartialTypeSignatures
• In the type ‘String -> _’
In the type signature: foo :: String -> _
|
78 | foo :: String -> _
| ^なるほど、 Int でした。ご苦労、コンパイラさん。書くべき型がピンと来ない場合、コ ンパイらが教えてくれます。しかも型だけでなく関数でも使えます:
Landing.hs:79:7: error:
• Found hole: _ :: [Char] -> Int
• In the first argument of ‘(.)’, namely ‘_’
In the expression: _ . ("Hello!" <>) . reverse
In an equation for ‘foo’: foo = _ . ("Hello!" <>) . reverse
• Valid hole fits include
foo :: String -> Int
read :: forall a. Read a => String -> a
genericLength :: forall i a. Num i => [a] -> i
length :: forall (t :: * -> *) a. Foldable t => t a -> Int
unsafeCoerce :: forall a b. a -> b
|
79 | foo = _ . ("Hello!" <>) . reverse
| ^length! よしこれで進める、などと。
見た目は?
HaskellはCやJavaみたいな {} 言語ではなく、上の例でも気づいたと思いますが割と簡潔 です。構造体の定義はこのように:
data OrgDateTime = OrgDateTime
{ dateDay :: Day
, dateDayOfWeek :: DayOfWeek
, dateTime :: Maybe OrgTime
, dateRepeat :: Maybe Repeater
, dateDelay :: Maybe Delay }
deriving stock (Eq, Show)日付のパーサー:
date :: Parser Day
date = fromGregorian <$> decimal <*> slashDec <*> slashDec
where
slashDec = char '-' *> decimalHTMLの雛形:
-- | Convert a parsed `OrgFile` into a full
-- HTML document readable in a browser.
html :: OrgStyle -> OrgFile -> Html ()
html os o@(OrgFile m _) = html_ $ do
head_ $ title_ (maybe "" toHtml $ M.lookup "TITLE" m)
body_ $ body os oテスト
Haskellはどう守ってくれる?
Haskellの強い静的型付けは業界上級です。副作用は堅く管理されて変数には変化があり 得ない事でデータが無定義の状態になってしまう事が殆どありません。 STM (Software Transactional Memory) によってデータをスレッド越しに共有するのも楽です。
どこでどうテストを書くのか?
単体テストは別のファイルで書きます。その位置もプロジェクト設定で指定しなければ実 行されません。普段なら tasty みたいなテスト・フレームワークが使われます:
import Test.Tasty
import Test.Tasty.HUnit
main :: IO ()
main = do
simple <- T.readFile "test/simple.org"
full <- T.readFile "test/test.org"
defaultMain $ suite simple full
suite :: T.Text -> T.Text -> TestTree
suite simple full = testGroup "Unit Tests"
[ testGroup "Basic Markup"
[ testCase "Header" $ parseMaybe (section 1) "* A" @?= Just (titled (Plain "A"))
, testCase "Header - Subsection" $ parseMaybe (section 1) "* A\n** B"
@?= Just ((titled (Plain "A")) { sectionDoc = OrgDoc [] [titled (Plain "B")] })
]
]すると、 stack test で実行。
Rustと違ってHaskellでは doctests を書くには ライブラリ が必要です。更に残念なの は単体テスト自体はテストするコードと別のファイルに置かなければならないせいでプラ イベート関数をテストするのは少し手間がかかります。
誤って遅いコードを書いてしまう頻度は?
一般的にHaskellのパフォーマンスは「充分に速い」レベルですが、真面目なHaskellソフ ト開発に当たると、気をつけなければならない遅延評価に関する落とし穴がいくつかあり ます。まず:
原則として先行的・正格的 fold を使う事
残念ながら標準ライブラリには遅延評価の効果で易々と裏切ってくれる関数があります。 foldl はその一つなので、代わりに foldl' を使いましょう。
できれば IO をストリーミングでやる事
大きなファイルやデータの流れを扱っている時は streaming みたいなライブラリを利用 すると、また厄介な遅延評価の影響で生じる問題を免れます。
ジェネリック過ぎるコードを書かない事
Rustと違いってHaskellではジェネリック関数は自動的にモノモーフィズム化されません。 たまにこのせいで関数が遅くなったりします。
CIは?
正式な Github Actions があって便利です。Stackやコンパイラなどのバージョンを指定 するのも自由です。ちなみにHaskell CIの詳しい記事は こちら.
協力
質問があればどこへ…?
公式な掲示板は The Haskell Discourse 。
Haskell自体のリリースなどの発表はどこで?
Discourse内の Announcements のところではコンパイラ以外にも色々と発表されますので 是非参考にしてください。環境の全体的な発展は Haskell State of the Union を。
環境の「小世界」の有無
やはり「小世界」が存在します。新プロジェクトに突入する前に決断しなければならないものがあります:
もちろん上のライブラリを一切使わない道もありますが、いずれも実際な開発経験に基づ いて作り出されたものなので使うのもためになります。
依存性の設定は?
依存性を含めて全てのプロジェクト設定は <プロジェクト名>.cabal ファイルで指定します。 このサイトもHaskellサーバーで、その設定はこのように:
executable server
hs-source-dirs: server
main-is: Main.hs
ghc-options: -threaded -with-rtsopts=-N -rtsopts
build-depends:
, bytestring
, directory ^>=1.3
, filepath ^>=1.4
, warp >=3.2 && <3.4バージョンの範囲の設定が見られます。これでも無事なコンパイルが保証されません。も し各依存性の更なる依存性のバージョンがお互いに一致しなければコンパイルできません。
この厄介を免れるために stack とStackageが生まれました。「Stackage Snapshot」に登 録されたパッケージは必ずコンパイルし合ってテストも成功します。最近のSnapshotには 3千近くのパッケージが登録されてあって使いたいものは大体入っています。
もし必要なバージョンなどがなければ stack.yaml で上書きできます:
resolver: lts-18.22
extra-deps:
# --- Missing from Stackage --- #
- org-mode-1.1.1
- org-mode-lucid-1.6.0
- skylighting-lucid-1.0.1
- xmlbf-0.6.1更に stack.yaml によってプロジェクトの「Workspace」が指定できます。それは複数の ライブラリやバイナリが同じプロジェクトに宿る事です。 cabal の方では cabal.project ファイルが似たような役割をします。
出荷
プロジェクトをどう出荷する?
Haskellのパッケージは Hackage に登載されます。一度登録したら新しいパッケージを出 荷するのは簡単です:
stack upload
結果は このようなページ です。アップデートする時も同じコマンドでできます。
ドキュメンテーションの仕方や文化は?
ドキュメンテーションに関してはHaskellは上級に入ります。型に慣れると信用するよう になって、他人のコードの型を見ただけで関数が丸ごと分かる現象が起こります。関数の 一々の詳細を確認しなくてもそのまま使えるとなると開発がどんなに加速するものか。
主なドキュメンテーション・ツールが二つあります: Haddock と Hoogle
stack haddock --open <プロジェクト名>
これで自分のプロジェクトとその依存性のドキュメンテーションがリンクされ、一体とし てコンパイルされます。完成するとブラウザで開かれて、下の例のようなページが見られます。 もちろんソースは確認できますが普段は型とその説だけで使えるに充分です:
では Hoogle へ。
stack hoogle --server
Hoogle では関数をもちろん名前で検索できますが、特別なのは関数の型で検索できる機能 です。例えば「 SemVer を Text にしてくれる関数は存在するだろうか」という問いに:
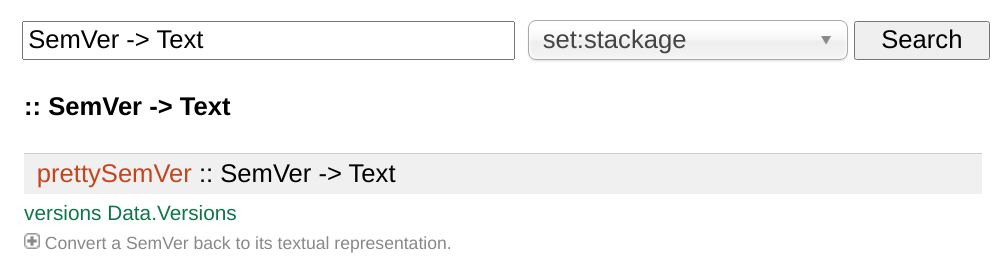
検索先は本プロジェクトとその依存性です。 オンライン版 を使えばHaskellライブラリの 全環境に亘って検索できます。
基本的にHaskellでは「機能の発見」が他所より簡単だと思います。
古い依存性のせいでプロジェクトが滞ったりする事は?
これはStackageのお陰で基本的にありません。Snapshotは頻繁に更新されますし、 依存性で問題が迫る時は 充分前に警戒が出されます 。
出荷用のバイナリをどうコンパイルする?
stack build だけです。 -O2 でコンパイルされ、自動的に strip もされます。
更にバイナリを圧縮するにはこの stack.yaml の設定が役に立ちます:
これでバイナリの大きさが半分ほど減ります。
出荷対象のOSごとに注意点などある?
どのOSでも stack と cabal のコマンドが同じですが、歴史的にはWindowsでHaskellをや るのは困難だったそうです。現在ARMやアップリのM1でもコンパイラーが対応しているの で基本的に問題ありません。
保守
Haskellはよくクラッシュする言語?
一般的にHaskellのプログラムは極めて安定しています。
Haskellには null の概念がないのでエラーは型システムで管理されます。Exceptionsも ない、という小さな嘘を信じても大体損はしませんがランタイムが扱う特別な IO Exceptionsは実はあり得ます。
具体的なクラッシュ方法としては:
…パターン・マッチのブランチを忘れてしまう事!
data Colour = Red | Green | Blue
-- 可能な値は三つあるのに二つしかマッチしていない。
-- RustやElmではコンパイル時のエラーになるがHaskellではただの警告!
foo :: Colour -> IO ()
foo c = case c of
Red -> putStrLn "It's red!"
Green -> putStrLn "It's green!"
-- クラッシュ!
main :: IO ()
main = foo Blue…または関数に undefined を残してしまう事!
-- まぁ詳しいコードは後でいいや、と。
solveWorldPeace :: Double -> IO ()
solveWorldPeace money = undefined
-- クラッシュ!
main :: IO ()
main = do
money <- getTheFunding
solveWorldPeace money…または特定の「やばい関数」を呼ぶ事!
> head $ take 0 [1..] Exception: Prelude.head: empty list
しかし:
- コンパイラの忠告のお陰でパターン・マッチの見落としは基本ない事。
- 残された
undefinedはテストはCIですぐバレてしまう事。 headなどの危険な関数はプロの開発者がよく承知しているので避けるのも自然な事。
なのでこのようなクラッシュ源は日常的なHaskellでは心配のない事です。よほど頑張ら ないとHaskellのプログラムはクラッシュしません。
「bitrot」の危機は?環境の発展で取り残される恐れは?
プログラムの予想される寿命は何十年であればこの事を真剣に配慮するのが最優先だと私 は思います。 他の記事 で説明したように、ツールや依存性の更新をあまりに先延ばしにす ると言語の環境に置いて行かれる危険があります。
Stackage はコンパイラのバージョンごとに別々のLTSを提供しているため…
…を stack.yaml に指定しただけでコンパイラと依存性の決まったバージョンがダウンロー ドされます。定期的にLTSのバージョンを更新しておいたら置いて行かれる事はまずあり ません。更新しなくてもLTSの文字通り(英:Long Term Support)、そのまま古いコンパ イラと依存性でコンパイルし続けられる事が保証されます。
コンパイラと言語そのものは”優しく”進化していきます。新しい機能が出ても既存の機能 が壊れる事は基本ありません。
言語とStackageの発展は この記事 で観察できます。
コードの「読みやすさ」をどう保つ?
Haskellにはメソッドがないので、構造体のデータを扱うには並みの関数が必要です。し かも関数であるためその名前が独特でなければだめですね。
data Person = Person { name :: String }
reverseName :: Person -> String
reverseName p = reverse (name p)ここでは name はただの関数となります。型は Person -> String 。
Record Dot Syntax Proposal によってメソッドに似た構造体関数の呼び方の導入が計ら れています。それまではよく「qualified imports」で関数名が独特にされます:
import qualified Data.Text as T
twoLengths :: String -> (Int, Int)
twoLengths s = (length s, T.length t)
where
t :: T.Text
t = T.pack slength という関数はここで二つありますが、読む我々にとってもコンパイラにとっても 区別が明白です。
Haskellの読みやすさその簡潔からなります。上の reverseName はこのようにも書けました:
. は合成の演算子です。
要らないコードをどう発見して削除する?
Haskellの「死んだコード分析」(英:Dead Code Analysis)は強いものです。普段指定 している警告設定は下記の通りです:
ghc-options: -Wall -Wpartial-fields -Wincomplete-record-updates -Wincomplete-uni-patterns -Widentities -funclutter-valid-hole-fits
妙な事に -Wall は「全部」ではありません。そもそもこういう設定は自動であるべきなのでは?
結論
Haskellは本物のソフト開発に適した言語環境です。活発なコア・チーム、 財団 、コミュ ニティを有して世界中で使われている言語です。Haskellのお陰で私は開発者として大幅 成長しましたし、Haskellで出荷したプロジェクトが採用に繋がったに違いありません。
試してみる損はないでしょう。思いがけない経験があなたを待っている事を保証します。