Haskellで漢字分析
私は最初に真面目に作ったHaskellプログラムは「NanQ」と名付けました。「何級」の言 葉遊びですね。日本語を入力すると漢字が級別に分かれて出されるプログラムでした。 「級」とは勿論、日本漢字能力検定(愛称「漢検」)の級のこと。
漢検
毎年約3百万人の受験者を誇り、殆どの日本人に聞いたことがあるだろう漢検。漢字の読 み書きができなければ日本での生活は痛い程難しいでしょう。ある級を合格していないと、 雇ってくれない会社もあるらしいです。この状態が判った上で何十年も学習する日本の学 生にとって漢検が良い勉強目標になると言えます。
検定には級が十から一まであり、三級と二級の間に「準二級」も、二級と一級の間に「準 一級」もあります。最初の六級(十から五)は小学校の各学年で学ぶ漢字とぴったり当て はまります。十級は一番簡単で80字だけ要されます。大人は普段二級(2136字・い わゆる常用漢字)まで目指しますが、そこまで辿り着くのは決して楽ではありません。 2012年の級別合格率は以下の通りでした:
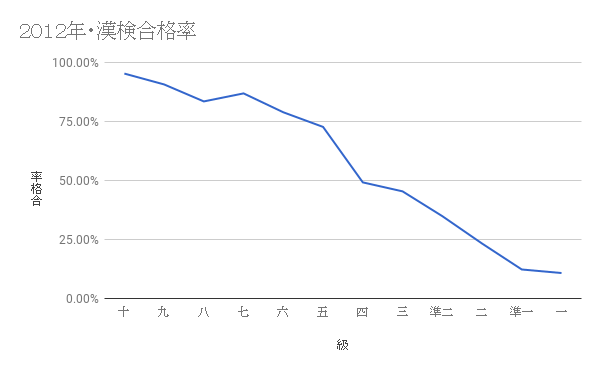
見ての通り二級を受ける四割以下の人は合格します。国語の先生の私の友人でもかなり勉 強してから二級が取れました。
二級で常用漢字が纏まれば、その先には何があるでしょうか。ますます不思議な、いずれ も中国語とほぼ変わらない字の海。検定の一級は六千字を要します。中国語圏の国の政府 はそれぞれ六千字から七千字を「常用」とするのは偶然とは思えません。勿論、中国系の 言語には漢字意外に書く方法はないので、六千も使われるのは当たり前でしょうか。
好奇心と分析
検定が試すのは漢字それぞれの読み書きだけではありません。用語、四字熟語、対義語、 類義語、文での使い方などが含まれます。
私は日本で働いていた頃、よく暇で漢字勉強をしていました。ある日突然思いつきました: 自分の書く文には漢検のどの級のどの漢字が使われているだろう・生徒が書く文は?・小 説などは?・常用漢字とは文字通り日常的なのか?最初に「NanQ」みたいなプログラムを 作ろうと思ったのはこの疑問がきっかけでした。
それは2011年の事でした。現在、その「NanQ」が kanji (Haskell, Rust) という ライブラリとして存在します。それを利用して文を分析するツールを作り、有名な文章を 入力すると気になる結果が出ました。
最初の結果
ドラえもんのウィキペディア記事を入力すると:
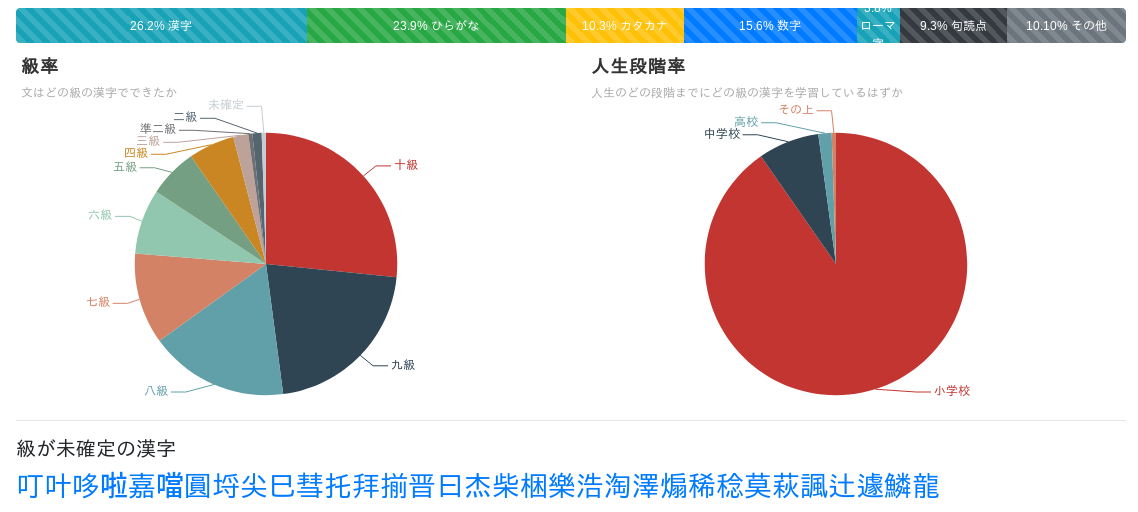
文は殆ど小学校レベルの漢字でできているようです。より具体的に言うと:
結果その1:平均的に日本語の文に現れる漢字は八割以上小学校で学ぶ字。
誤解に気をつけましょう。八割の 言葉 が小学校漢字だけでできているという意味では ありません。「唯一」は良い例になります。「唯」は準二級で「一」は十級です。小学校 漢字(ただ1026字!)のみで一人前になれないでしょう。
ウィキペディア全記事の分析
しかしその「八割」とはなぜ断言できるでしょうか。
ウィキのデータベース・ダンプ から 字だけ抽出する のは結構簡単と半分偶然で発見しました。
> python WikiExtractor.py --json \
--processes 4 \
--output out/ \
jawiki-20180301-pages-articles-multistream.xml
INFO: Finished 4-process extraction of 1097409 articles2018年3月初日のダンプ(100万以上の記事!)の10.3gbのXMLから2.5gbのJSONが 誕生しました。一行の例は以下の様:
{
"id": "5",
"url": "https://ja.wikipedia.org/wiki?curid=5",
"title": "アンパサンド",
"text": "アンパサンド..."
}とても処理しやすいフォーマットです。 kanji を使って全記事を分析すると:
> stack exec -- jp-wiki Starting... Elementary: 86.299255 Middle School: 7.0112896 High School: 3.1226614 Above Joyo: 3.5650756 Complete.
結果その2:平均的にウィキペディアの記事には高校で学ぶ漢字より常用意外の漢字の方が多い。
なぜでしょう。思いつくのは:
- 人名。日本人の名前によく珍しい字が出ます。例えば「澤田」。「澤」とは常用漢字で はありませんが名字としてはそれ程珍しくありません。一人生を生き、何千人と出会い、 この「澤」が読めない高齢者はいないでしょう。
- ウィキペディアの記事はどちらかというと学者風に書かれる事。テーマが 輪廻 でも 屁 でも小学生が読めそうにない内容です。ウィキではなく100万冊の漫画を分析したら 割合は上と異なるでしょう。
- 人間は学ぶ動物である事。もう二千字を習った身ならたまに新しいのを取り入れるのは 苦労ではないでしょう。特に「読み・認識」のためだけであれば。
それでも少し計算してみましょう。
| 人生段階 | 習った(はずの)字数 | 常用漢字の何割 | 使われる割合 |
|---|---|---|---|
| 小学校 | 1,026 | 48.0% | 86.3% |
| 中学校 | 597 | 27.9% | 7.0% |
| 高校 (とそれ以上) | 513 | 24.0% | 3.1% |
怪しくありませんか。
分析の続きと提案
個人にも社会にも高い基準が大事だと私は思います。基準があって目標ができ、人間は栄 えます。私個人の判断であれば上の謎の3.5%を含めるように常用漢字を 増やします 。 結果その2 から判ったのは漢検の上級(3級・準二級・二級・準一級)の字の順番を 正す必要もあるように見えます。しかし正す道は険しい。気をつけないといけないのは:
- 「唯一」のように極普通の言葉がどう漢検の級を及ぶか。
- 字それぞれがどの頻繁で現れるか。それを元に順番を固定するか、「いや珍しくても日 本人として習うべきだ」という考えであまり使わない字やその四字熟語を人工的に入れ るか。
- どの漢字には「頻繁バブル」があるか。例えばある科学の分野、漫画、スポーツ等ではどの漢字が普段より 頻繁に出てくるのをどう扱うか。
答えは私には判りませんが、常用漢字を正そうと思う組織がどこかあれば、上の問題に対 面しなければならないと思います。