- Haskell for Software Development
- Programming
- How are new projects created and compiled?
- How is the moment-by-moment programming experience?
- What language idioms are available?
- Is it verbose? Is it alright to look at?
- Testing
- How does the language protect me from myself?
- How are tests written, and where?
- Is it easy to write slow code?
- What is the CI situation?
- Collaborating
- Where do I find answers to my questions?
- How do I track changes to Haskell itself?
- Are there competing paradigms to write Haskell?
- How do I depend on other libraries?
- Releasing
- How are Haskell projects published?
- How do I document a project?
- Can a single old dependency hold the whole ecosystem back?
- How do I produce an optimized release binary?
- How do I develop and release Haskell on non-Linux systems?
- Maintenance
- Conclusion
Software Development Languages: Haskell
By Colin on 2022-01-26
Welcome to the next installment of a series that discusses certain languages and their viability for long-term software development. If you missed the earlier articles, here they are:
- Part 1: Software Development Languages
- Part 2: Rust
This time we're talking about Haskell.
Hey, don't you need a PhD to write anything in Haskell?
Not at all! Haskell is an active language used all over the world by normal developers. Code is clean and fast, there are libraries for anything you'd want to do, its concurrency idioms are nearly best-in-class, and maintenance/refactors are much cheaper than some other languages.
The sections below don't need to be read in order. Feel free to jump around to what interests you via the Table of Contents.
Haskell for Software Development
Programming
How are new projects created and compiled?
Haskell has two main tools for managing projects, Cabal and Stack. These tools share some internals and accomplish the same tasks of dependency management and project building, although they differ in some aspects of UI/UX.
By default, Cabal sources dependencies directly from Hackage, the official repository for all published Haskell packages. On the other hand, Stack works with fixed package sets defined on Stackage. These sets offer a stability guarantee that all packages in the set satisfy each other's version bounds, and they all compile and pass tests together. Even with Stack(age), dependency code itself is still pulled from Hackage in the end.
Which should you choose? It depends on your requirements:
- Do you want total control over your dependencies, with the newest available versions always at your fingertips? Then go with Cabal.
- Do you want access to long-term community-curated package sets, even if that means you might not be getting the absolute newest dependency versions? Then go with Stack.
- Addendum: Are you on Arch Linux? Then use Stack installed via the stack-static package. Unfortunately the Arch maintainers made an error in judgement several years ago which can result in
cabalusage conflicting with system packages in ways that cause undefined breakage. This is not Cabal's fault per se, but everyone has long since moved to Stack to avoid the headache.
Otherwise, toss a coin! Both tools work fine and have active communities. Usage examples for the rest of the guide (few as they are) will use stack, although comparable commands exist for cabal.
To create a new project:
stack new <project-name> simple
This generates:
. ├── foobar.cabal ├── LICENSE ├── README.md ├── Setup.hs ├── src │ └── Main.hs └── stack.yaml
Which can be compiled via stack build, tested with stack test, or ran as-is with stack run. Pass --fast to any of these to compile without optimizations.
How is the moment-by-moment programming experience?
Haskell has an LSP, which is most easily installed via ghcup:
ghcup install hls
Upon opening a Haskell file in your editor the LSP will detect your project setup and work as you'd expect.
Alongside an LSP, it's often handy to have an open typechecking loop in a separate terminal. ghcid fills this role nicely, listening for file changes and informing you immediately of errors without fully compiling:
server/Main.hs:(62,10)-(64,41): warning: [-Wincomplete-patterns]
Pattern match(es) are non-exhaustive
In a case alternative: Patterns not matched: English
|
62 | ps = case l of
| ^^^^^^^^^...People say that prototyping is faster with dynamic languages. Others theorize that those feelings are born from years of type-trauma caused by Java and C++, where the contrast brought by Python/Lisp/etc. is so stark as to invoke a religious experience. On the other hand, I find "Type-driven prototyping" with Haskell to be quite efficient. Haskell's type system is truly on your side. Consider:
-- Perhaps we're not done with this type definition,
-- but we at least know that we want a `name` field.
data Person = Person { name :: String }
-- We don't know what we want our `Family` type to contain,
-- so we leave it blank for now.
data Family
-- Given a name, try to lookup the corresponding `Person`.
person :: String -> IO (Maybe Person)
person = undefined
-- If we have a person, we can then look up their family.
-- Implementation details irrelevant for now.
family :: Person -> IO Family
family = undefined
-- Finally, "purely" form a graph of the `Person`
-- relations in a `Family`.
relations :: Family -> Graph Person
relations = undefinedIt's common to continue this way and "implement" a good portion of a program without actually committing to details. This lets us iterate rapidly on changes to types and function signatures. And since Haskell is so compact, our program skeleton can end up being quite tidy.
What language idioms are available?
Firstly, Haskell is strongly-typed and has Garbage Collection managed by a runtime.
Learning Haskell will expand your mind as it is built upon foundational principles often not found in other languages. The critical three are:
- Immutability
- Laziness
- Function Purity
When brought together these form a special world to program in. Let's expand on them to see why. First of all:
Variables do not mutate.
This isn't the opt-out mutability of Scala, or the opt-in mutability of Rust. In Haskell, variables cannot be mutated. Further, there are no loops, so the usual "loop through an array and mutate some stuff" approach to many problems is simply not possible. Luckily there are (superior) alternatives, and once you're used to them, you don't miss loops at all.
Next we have:
All function calls are lazy.
Function results are not computed until they're absolutely needed, and this is tracked by the runtime. This has wonderful implications for how data structures and recursion behave. Want to see a list of all the Fibonacci Numbers?
This is a list with a self-referential definition. How long is it? Infinitely, of course! But that doesn't stop us from passing it around like a normal list. We can get some elements from it easily enough:
> take 10 fibs [0,1,1,2,3,5,8,13,21,34] > fibs !! 100 354224848179261915075
We're fine so long as we don't try to sum it or calculate its length...
And lastly:
All effects are tracked in the type system.
This is another way of saying that "functions are pure". Check out the following code:
-- | This function _cannot_ perform IO.
add2 :: Int -> Int
add2 n = n + 2
-- | This function can!
addThenPrint :: Int -> IO ()
addThenPrint n = do
let m = add2 n
print madd2 has no "side effects", something we can guarantee without actually looking at the internals of the function. The function signature tells us everything: Int -> Int. Give an Int, get an Int. addThenPrint on the other hand can perform IO actions, and we can see this from its signature. There are of course more "effects" than IO, but it's the main one for doing real work.
Why be explicit with effects like this? It actually helps both you and the compiler. You, because it helps you keep your code better organised, reducing the cost of maintenance. The compiler, because it can inline things better.
Otherwise, Haskell has many of the modern conveniences: powerful structs and enums, pattern matching, powerful generics (i.e. Typeclasses and Type Families), and (typeclass) derivation. Bye-bye boilerplate! You may have heard of things like "Monads" before, but these and other features are nothing but facilities to help you pipe your effectful code together.
However, Haskell has something that almost no other language boasts: hole fits. I miss these most when I'm working in other languages. Let the compiler tell you what it wants!
Landing.hs:78:18: error:
• Found type wildcard ‘_’ standing for ‘Int’
To use the inferred type, enable PartialTypeSignatures
• In the type ‘String -> _’
In the type signature: foo :: String -> _
|
78 | foo :: String -> _
| ^So it's an Int! Thanks Haskell. But wait, we can go the other way too. If we know the types we want but can't remember the functions...
Landing.hs:79:7: error:
• Found hole: _ :: [Char] -> Int
• In the first argument of ‘(.)’, namely ‘_’
In the expression: _ . ("Hello!" <>) . reverse
In an equation for ‘foo’: foo = _ . ("Hello!" <>) . reverse
• Valid hole fits include
foo :: String -> Int
read :: forall a. Read a => String -> a
genericLength :: forall i a. Num i => [a] -> i
length :: forall (t :: * -> *) a. Foldable t => t a -> Int
unsafeCoerce :: forall a b. a -> b
|
79 | foo = _ . ("Hello!" <>) . reverse
| ^And sure enough it suggests length, exactly what I was looking for.
Is it verbose? Is it alright to look at?
Haskell is not a "curly brace" language, and is quite compact. A struct definition:
data OrgDateTime = OrgDateTime
{ dateDay :: Day
, dateDayOfWeek :: DayOfWeek
, dateTime :: Maybe OrgTime
, dateRepeat :: Maybe Repeater
, dateDelay :: Maybe Delay }
deriving stock (Eq, Show)A date parser:
date :: Parser Day
date = fromGregorian <$> decimal <*> slashDec <*> slashDec
where
slashDec = char '-' *> decimalSome HTML templating:
-- | Convert a parsed `OrgFile` into a full
-- HTML document readable in a browser.
html :: OrgStyle -> OrgFile -> Html ()
html os o@(OrgFile m _) = html_ $ do
head_ $ title_ (maybe "" toHtml $ M.lookup "TITLE" m)
body_ $ body os oThe Haskell LSP has a baked-in auto-formatter, so code stays neat.
Testing
How does the language protect me from myself?
Haskell has one of the strongest type systems. Thanks to explicit effect management and no mutability, it's very difficult to reach an undefined state with your data. STM (Software Transactional Memory) can be used to share data reliably across threads.
How are tests written, and where?
Unit tests are written in a separate file, and your project config needs to be told that there are tests there. It's customary to use a framework like tasty to help write them:
import Test.Tasty
import Test.Tasty.HUnit
main :: IO ()
main = do
simple <- T.readFile "test/simple.org"
full <- T.readFile "test/test.org"
defaultMain $ suite simple full
suite :: T.Text -> T.Text -> TestTree
suite simple full = testGroup "Unit Tests"
[ testGroup "Basic Markup"
[ testCase "Header" $ parseMaybe (section 1) "* A" @?= Just (titled (Plain "A"))
, testCase "Header - Subsection" $ parseMaybe (section 1) "* A\n** B"
@?= Just ((titled (Plain "A")) { sectionDoc = OrgDoc [] [titled (Plain "B")] })
]
]stack test then does what you'd expect.
Unlike Rust, Haskell does not have first-class doctests, but they can be added via the doctest library. Also unlike Rust, one can't write tests in the same file as the function they're testing, so writing tests for unexported functions is a notorious pain.
Is it easy to write slow code?
Overall Haskell performs quite well, but there are some caveats involving laziness that professional Haskellers need to keep in mind when writing production software. Three that come to mind are:
Always use strict folds.
There are unfortunately some functions in the Standard Library that betray beginners with their laziness behaviour.
Do streaming IO whenever possible.
Use libraries like streaming when dealing with large files or continuous flows of data. There are edge-cases involving Lazy IO that you don't want to involve yourself with.
Avoid being overly generic.
Unlike Rust, Haskell does not automatically monomorphise its generic functions. Sometimes there can be unexpected slowdowns in functions that specify their arguments in terms of typeclass parameters instead of concrete types.
What is the CI situation?
Haskell has good first-class Github Actions that allow you to cleanly specify the exact versions of Stack/Cabal/GHC you wish to test with. In fact, I have another article all about it.
Collaborating
Where do I find answers to my questions?
The Haskell Discourse is the official place for asking questions.
How do I track changes to Haskell itself?
The Announcements area of the Discourse is good for tracking a variety of ecosystem updates, not just the compiler. How the overall ecosystem is doing can be tracked by the community maintained Haskell State of the Union or Awesome Haskell.
Are there competing paradigms to write Haskell?
There do exist a few "microecosystems" within Haskell. When starting a serious project, one must decide up-front:
- Are we using lenses at all? (See also microlens)
- Are we streaming via the streaming, pipes, or conduit ecosystems?
- Are we managing effects via rio, mtl, or one of the Extensible Effects libs?
It's also possible to use none of these, although they were all built to solve genuine problems that arose from real-world software development.
How do I depend on other libraries?
Whether you use cabal or not, dependencies are specified in the <project-name>.cabal file. Here's a sample from this website (which is a Haskell server):
executable server
hs-source-dirs: server
main-is: Main.hs
ghc-options: -threaded -with-rtsopts=-N -rtsopts
build-depends:
, bytestring
, directory ^>=1.3
, filepath ^>=1.4
, warp >=3.2 && <3.4Here we can see me setting some dependency ranges, which helps the build tools determine the best combination of dependency versions to pull. This is important, as for Haskell, only one copy of each dependency may be present in the build environment, and thus all the mutually dependent packages must agree on versions.
If that sounds like a headache and a potential source of problems, well, it was. stack and Stackage were invented to solve precisely this problem. Namely, they provide sets of package "snapshots" - listings of specific packages and versions that are known to compile and pass tests as a group. Not all available packages are present in these snapshots, but as of this writing, the most recent one has over 2700 packages, so what you want is almost certainly there.
If a package you need is missing, or you want a different version, you can specify an override within your project's stack.yaml:
resolver: lts-18.22
extra-deps:
# --- Missing from Stackage --- #
- org-mode-1.1.1
- org-mode-lucid-1.6.0
- skylighting-lucid-1.0.1
- xmlbf-0.6.1A stack.yaml is also used to configure a project "workspace" - multiple libraries/executables in the same logical project. Cabal also accepts a cabal.project file for a similar purpose.
Releasing
How are Haskell projects published?
Haskell packages are hosted on Hackage. After making an account, a new package can be pushed (or updated) via:
stack upload
The result is a page like this listing all available versions and other package metadata. Hackage even provides a build matrix to show you how compatible your package is with various versions of the compiler!
How do I document a project?
Haskell is in the best-of-class category when it comes to documentation. Haskell's type system quickly earns your trust, and once it does, you almost never need to read someone else's code in order to understand it; you can just read the type signatures shown in the docs and get on with your life. There are languages whose type signatures do not tell you the full truth, which fosters fear and distrust, but Haskell is not like this.
Haskell provides two main doc tools, Haddock and Hoogle:
stack haddock --open <your-project>
This will build a local copy of your project's docs linked to the exact versions of all the dependencies you're using. The --open then opens them in your browser. This means you're never accidentally looking at stale (or too new!) versions of third-party APIs.
Here is an example from a library of mine. On a doc page you can view the source if you like, but the types often tell you all you need:
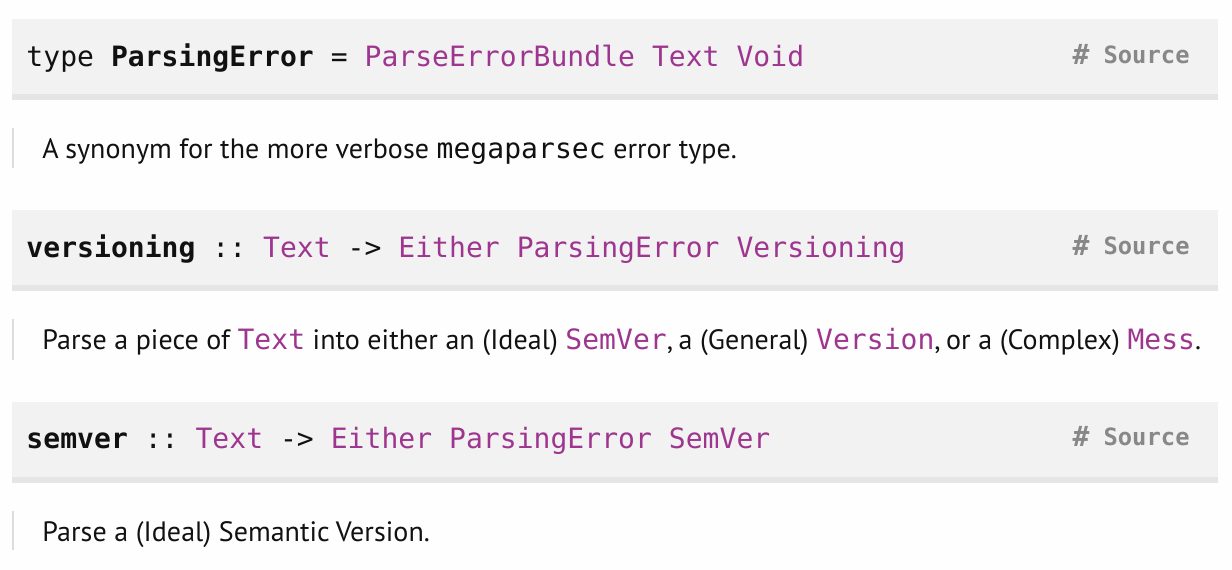
Now onto Hoogle.
stack hoogle --server
This runs a Hoogle Server based on your project and its dependencies. I have seen something like Hoogle in no other language; it lets you perform general API searches across libraries based on types, including function types. To the question "is there any function, anywhere, that turns SemVer into Text? " we can do:
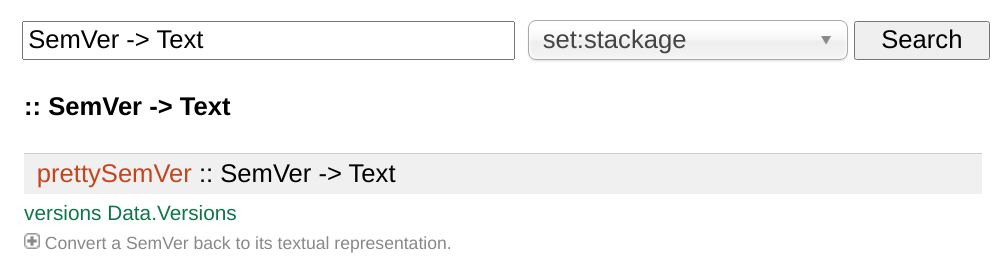
You can even add generic parameters to your searches. Hoogle even has an online version if you don't feel like running a local copy.
Overall the ability to discover functionality is very high in Haskell.
Can a single old dependency hold the whole ecosystem back?
Thanks to Stackage, this is generally not the case. And thanks to the effort of Stackage's tireless volunteers, package maintainers get early warning of critical API changes and broken upstream dependency bounds.
How do I produce an optimized release binary?
stack build. By default this builds your application with -O2. It also strips your binary for you.
To further reduce final binary size, it's a good idea to add the following to your stack.yaml:
This ensures that all dependencies are compiled with the -split-sections flag, allowing the compiler's specializer and inliner to do more effective work. This typically reduces final binary size by at least half.
How do I develop and release Haskell on non-Linux systems?
stack and cabal commands are the same regardless of platform, although Haskell has had a troubled past with Windows. These days, versions of the compiler and tooling are available for ARM, Apple's newer M1 processor, you name it.
Maintenance
Does Haskell code crash a lot?
In general, Haskell programs are extremely stable.
Haskell has no concept of null, so errors are tracked through the type system using concrete types, like a number of modern languages do. We can mostly pretend there are no Exceptions either, although there do exist certain IO exceptions which are treated specially by the runtime. Otherwise, we can crash a program by:
... missing a pattern-match branch!
data Colour = Red | Green | Blue
-- I've only matched two of the three possibilities. This is only
-- a warning in Haskell, not a hard error like Rust or Elm!
foo :: Colour -> IO ()
foo c = case c of
Red -> putStrLn "It's red!"
Green -> putStrLn "It's green!"
-- This will crash!
main :: IO ()
main = foo Blue... or by calling a function we forgot to implement!
-- TODO Implement later once I figure this out.
solveWorldPeace :: Double -> IO ()
solveWorldPeace money = undefined
-- This will crash!
main :: IO ()
main = do
money <- getTheFunding
solveWorldPeace money... or by calling certain naughty functions!
> head $ take 0 [1..] Exception: Prelude.head: empty list
But:
- The compiler warns you loudly if you forget a match pattern.
- A left-over
undefinedgets discovered almost immediately through your own tests or CI. - Working devs are well aware of pitfalls like
headand are used to avoiding them.
So these aren't a source of daily concern. And of course writing bad FFI code and mucking with exposed C pointers is a great way to crash, but that's also not a concern for most people.
How much of a threat is bitrot? Will the ecosystem leave me behind?
This is one of the most important aspects of development when considering software intended to last decades. As I described in another article, a language's ecosystem can "leave you behind" if you wait too long to upgrade your toolchain / dependencies.
Stackage has separate LTS major versions for each main compiler version. By setting your LTS...
... stack pulls down the corresponding compiler and all the deps your project needs. So long as you occasionally bump this LTS, you're guaranteed to stay current. And even if you don't, the entire premise of these snapshots is to ensure your project will compile far into the future!
The compiler itself is fairly backwards compatible. Changes to the bundled Standard Library come now and again, but they're done in controlled waves as to avoid breakage.
The relationship between the compiler, its changes, and Stackage can be tracked here.
How does code stay readable?
Unfortunately Haskell does not have "methods", and all Record (struct) field accessors are actually functions whose names you must make unique.
data Person = Person { name :: String }
reverseName :: Person -> String
reverseName p = reverse (name p)name here is a top-level function of the type Person -> String.
The Record Dot Syntax Proposal is aiming to rectify this, however. In the meantime, "qualified imports" are often used to maintain function name uniqueness within the imported namespace:
import qualified Data.Text as T
twoLengths :: String -> (Int, Int)
twoLengths s = (length s, T.length t)
where
t :: T.Text
t = T.pack sWe've called two different length functions, but it's clear to us (and the compiler) which is which. Here we can see also a where clause, used to keep details out of the main function body.
In general though, Haskell's readability comes from its terseness. The above reverseName function could instead be written:
Using what's called "point-free syntax". . is the function composition operator.
How do I get rid of code I don't need?
Haskell has decent dead-code analysis and a good set of warnings. Here are the warnings I typically turn on, set in my Cabal file:
ghc-options: -Wall -Wpartial-fields -Wincomplete-record-updates -Wincomplete-uni-patterns -Widentities -funclutter-valid-hole-fits
Although it's strange that -Wall isn't actually everything! I think I prefer Rust's approach of "warning about everything unless told not to".
Conclusion
Haskell is a powerful tool for real software development. It has an active core team, Foundation, community, and companies that use it all over the world. My experience with it has shaped who am I as a programmer, and has had no small part in landing me jobs, be they Haskell positions or not!
For Haskell, I say: try it. It will force you to program in a way you didn't know you needed to.
- Part 1: Software Development Languages
- Part 2: Rust
If you liked the article, consider sending me a coffee!