Japanese Kanji Analysis with Haskell
My first real Haskell program was called NanQ, a pun of the Japanese word 何級 ("nan-kyuu") meaning "which level". Given some Japanese text on the command line, it would spit out which "level" each Kanji belonged to. Here "level" refers to groupings of Kanji by complexity / rarity as defined by the Japan Kanji Aptitude Testing Foundation for their "Kanken".
Kanken - The Japan Kanji Aptitude Test
Most Japanese have heard of this. Around 3 million people (mostly Japanese) take it every year. Since Kanji knowledge is critical for basic literacy in Japan, and so everyone must learn them, the Kanken works well as a study goal. Some companies even require you to pass certain levels before offering employment.
The test has 12 levels: 10 to 3, Pre-2, 2, Pre-1, and 1. The first 6 six of these correspond directly to the Kanji learned in the 6 years of Japanese elementary school. Level 10 is the simplest, asking for knowledge of only 80 Kanji. Adults tend to go as far as Level 2, which asks for 2,136 Kanji, the standard set defined by the Ministry of Education. However, getting that far isn't simple. Here are the pass rates for the year 2012:
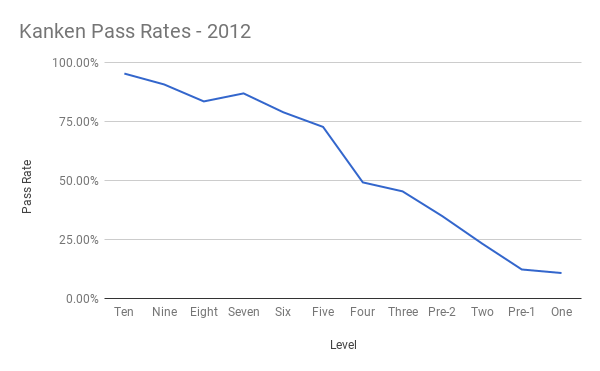
Less than 25% of people who take Level 2 pass it. A friend of mine, a native teacher of Japanese herself, had to study considerably before being able to pass Level 2. I was able to get to Pre-2.
What's beyond Level 2? A deep well of increasingly obscure Kanji which essentially amounts to Chinese. Level 1 of the test asks for around 6,000 Kanji. Perhaps not coincidentally, various governments of the Chinese-speaking world list between 6 and 7 thousand characters as their own standard sets. More characters are necessary for them, since Chinese languages have no other way to write.
Curiosity and Analysis
The tests don't just probe your ability to read and write single Kanji in isolation. Also examined is the ability to use them in compounds, produce 4-symbol poetic idioms known as 四字熟語 (yo-ji-juku-go), and demonstrate knowledge of synonyms and antonyms, among other things.
While working in Japan and studying Kanji in my free time, I became curious. How much Kanji of each level was I producing in my own writing? How about my students, who were young, but native speakers? How about "real" texts, like newspapers? Do the levels defined by the Ministry of Education match how Japanese Kanji are really used? Answering these questions was my original motivation for writing NanQ.
I came back to that project every few years to give it a spruce up. Today it survives in the form of my kanji Haskell library, and a demo available from the home page of my site, https://fosskers.ca. Check for Kanji Analysis under the Tools tab.
Initial Results
Here's a screenshot of the demo having been ran over the Wikipedia article for Doraemon, a popular children's manga and anime:
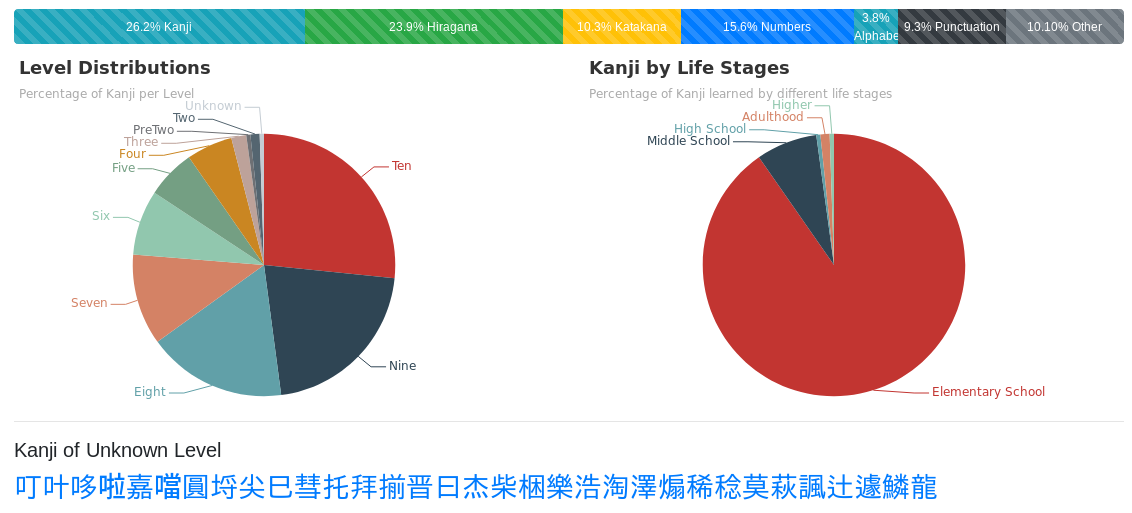
Levels 10 to 5 correspond to Kanji learned in elementary school. In this particular text, we see these elementary Kanji take up a vast majority of all Kanji used.
Observation 1: Kanji learned in elementary school make up, on average, 86% of all Kanji used in Japanese texts.
The wrong conclusion to draw from this would be that 86% of words are made up of only elementary Kanji. Words like 唯一 (yui-itsu, a word that everyone knows) throw this off: 一 is from Level 10, but 唯 is from Level Pre-2. So, we can't just learn the elementary Kanji and call that "good enough".
Analysing Japanese Wikipedia
Where does that 86% number come from?
I discovered that it was fairly simple to extract all text from Wikipedia database dumps:
> python WikiExtractor.py --json \
--processes 4 \
--output out/ \
jawiki-20180301-pages-articles-multistream.xml
INFO: Finished 4-process extraction of 1097409 articlesThis produced 2.5gb of JSON from 10.3gb of original XML, based on the 2018 March 1st dump of the entire Japanese Wikipedia (1,100,000 articles!). With the streaming library's support for attoparsec, it was simple to produce a Stream (Of Value) IO () that I could lens into and grab only the Text of the article body. Then, normal application of functions from my kanji library gives us aggregate information about the whole set:
> stack exec -- jp-wiki Starting... Elementary: 86.299255 Middle School: 7.0112896 High School: 3.1226614 Above Joyo: 3.5650756 Complete.
Observation 2: On average, Wikipedia articles contain more Kanji learned beyond High School than during it.
Once again, let's avoid over-extrapolating and consider:
- that articles frequently cite people's names, and Japanese names often contain rare Kanji. Take the last name 澤田 (Sawada): 澤 is not a Joyo Kanji, but it's a common enough last name that most people should be able to read it (especially after meeting thousands of people during one's lifetime).
- that Wikipedia is written academically, and that there are articles ranging from Category Theory to the Cycle of Buddhist Reincarnation to cell division to farts. If you instead scanned a million manga volumes, you'd likely end up with a different spread.
- the fact that humans learn. When you've learned 2,000 Kanji already, picking up a new one here and there (especially just for reading/recognition) is easy.
Still, let's run the numbers.
| Life Stage | Expected Kanji to Learn | Fraction of Joyo Total | Fraction Used |
|---|---|---|---|
| Elementary School | 1,006 | 47.1% | 86.3% |
| Middle School | 601 | 28.1% | 7.0% |
| High School (and beyond) | 529 | 24.8% | 3.1% |
Suspicious.
Further Work and Recommendations
Personally, I appreciate high standards. I think humans thrive under them. If it were my decision, I'd increase the number of Joyo Kanji to encompass more of the missing 3.5% we saw above. Observation 2 hints at the necessity of a reshuffling as well, but we would need more data for that. Namely:
- What distinct words of various rarities contain Kanji from each level? Recall 唯一.
- How often does each individual Kanji actually appear? Should absolute freqencies be the prime ordering criterion, or is a bit of prescriptivism good too (re: rare Kanji used in Yo-ji-juku-go that nobody really uses)?
- Which Kanji have "frequency bubbles"? Say, in what subcultures or academic disciplines do certain Kanji appear abnormally often? How should those affect the overall order?
I don't have answers to these questions, but anyone considering a reordering of the standard Kanji set would have to address them, or they risk wasting their time.