- Preface
- New Library:
mapalgebra - An Aside: The Haskell Language
- Features and Strengths
- Type Safety
- Lazy Rasters
- Free Parallelism
- Performance
- Small Library, Clear Documentation
- Low-effort Deployment
- Short-comings
- What about Rasterio (Python)?
- What about GeoTrellis (Scala)?
- Comparisons
Realistic Single-Server Raster Processing
By Colin on 2018-05-11
Preface
Some problems that have historically plagued raster processing systems are:
- not being able to fit large images into memory
- not being able to index the entire image (i.e. more pixels than a 32-bit
inttype) - burning time performing array algorithms serially
- intermediate memory allocation between operations
Long-running satellite imagery programs like Landsat and Sentinel continue to produce large imagery, so these problems remain relevant to modern systems. In this article I announce my new Haskell library mapalgebra, propose why Haskell is an excellent language for GIS work, and offer a (hopefully) fair comparison with existing Open Source solutions.
New Library: mapalgebra
mapalgebra is an implementation of Map Algebra as defined by C. Dana Tomlin in his classic text GIS and Cartographic Modeling. The library is built on the fantastic Parallel Array library massiv by Alexey Kuleshevich, and features op fusion (i.e. "lazy Rasters"), flexible Local Operations, extremely fast parallel Focal Operations, optional typesafe NoData handling, and the ability to process arbitrarily large Rasters on a single machine.
Zonal Operations are planned but not yet implemented in v0.1. Other aspects of GIS work outside of Map Algebra are not provided.
An Aside: The Haskell Language
Haskell was first released in 1990, and is a strongly-typed, lazy, purely functional language. These words mean specific things:
- Strongly-typed: All values have explicit types and the compiler is very strict about enforcing typing rules
- Lazy: Unneeded calculations are not performed
- Purely: Functions cannot mutate shared inputs nor affect global program state
- Functional: The fundamental units of program composition are functions, and these can be passed to or returned from other functions
To further differentiate Haskell from Object-Oriented languages (like Java) or Imperative ones (like C or Go), Haskell has no classes, loops, or mutable variables. Despite that, we are still able to write anything we would want to write, and the process is enjoyable. Haskell also boats a vast library ecosystem and excellent build tooling.
If you are unfamiliar with Haskell, this video by Derek Banas serves as a good introduction. To learn it in full, consider The Haskell Book by Chris Allen and Julie Moronuki. It starts at the foundations and offers no shortcuts.
To try or develop Haskell, the book (and I) recommend the Stack tool.
Features and Strengths
mapalgebra' s answer to the Raster processing problem? Be lazy™ and parallelize everything.
Type Safety
The fundamental type provided by mapalgebra is the Raster. Its full type signature can look like this:
Raster S WebMercator 256 256 Int
| | | | |
| | | | ---> Data type of each pixel
| | | ---> Raster columns
| | ---> Raster rows
| ---> Projection of the Raster
---> Current "memory mode".
`S` stands for the `Storable` typeclass, meaning
that this Raster is currently backed by a real
in-memory byte-packed Array.
This is either a freshly read image, or the result
of computing a "lazy" Raster.... or this...
Raster D LatLng 512 512 Word8
| |
| ---> A byte.
---> A "delayed" or "lazy" Raster.
Likely the result of some Local Operation.... or even this.
Raster DW p 65000 65000 (Maybe Double)
| | | |
| | | ---> Rasters are fully polymorphic
| | | and can hold any data type.
| | ---> Huge!
| ---> `p` is fine if you don't care about Projection.
---> A "windowed" Raster, the result of a Focal Op.So why all the type variables? Why isn't Raster Int sufficient? And why are there numbers in a type signature?
mapalgebra holds this as one of its fundamental assumptions:
Rasters of different size or projection are completely different types.
Unless your images have the same size and projection (or you've manipulated them so that they do), you can't perform Local Operations between them. This eliminates an entire class of bugs, and reduces complexity overall.
The numbers in the signatures are thanks to Haskell's DataKinds extension, which lets us promote values into types for the purposes of type checking.
Lazy Rasters
I mentioned Raster S above as being backed by real memory. In contrast, Raster D is a "delayed" or "lazy" Raster. Operations over/between lazy Rasters are always fused - they don't allocate additional memory between each step. Consider NDVI:
-- | Doesn't care about the projection or Raster size,
-- so long as they're all the same.
ndvi :: Raster D p r c Double
-> Raster D p r c Double
-> Raster D p r c Double
ndvi nir red = (nir - red) / (nir + red)Or the Enhanced Vegetation Index calculation:
-- | The constants are interpreted as lazy Rasters of only that value.
evi :: Raster D p r c Double
-> Raster D p r c Double
-> Raster D p r c Double
-> Raster D p r c Double
evi nir red blue = 2.5 * (numer / denom)
where numer = nir - red
denom = nir + (6 * red) - (7.5 * blue) + 1Here we see 8 binary operations being used, but none of them perform calculations or allocate new memory (yet). This saves a lot of time that would otherwise be spent iterating multiple times through the Array.
Only the application of the strict function on a Raster D or Raster DW will actually run anything and allocate a new underlying Array. For the purposes of GIS, that Array could have type S (Storable, for imagery IO. Primitive types only) or B (Boxed, for custom data types).
Free Parallelism
Good news: so long as you compile with -with-rtsopts=-N, code that uses mapalgebra will automatically utilize all of your CPUs for its calculations. No other special configuration, custom code, or developer overhead is required.
For production systems, this means informally that the more CPUs you throw at the problem, the faster it will get "for free". Please do take Amdahl's Law into account, though.
Performance
Decades of work have gone into GHC, the main Haskell compiler, and it can produce highly optimized machine code. Thanks to this, to Massiv, to some rewrites of mine, and to a lot of benchmarking, I've achieved speeds that are competitive-or-better than existing libraries in the field. Documenting the entire process helped greatly to prove which (and how) changes were useful.
Haskell also has an LLVM backend, which can be accessed with the -fllvm compiler flag. Not all operations benefit from it, but the ones that do gain about a 2x speed-up.
Performance comparisons between the libraries is available below in the Benchmarks section.
Small Library, Clear Documentation
I worked the entire library down to only 600 lines or so, while providing ample documentation and examples.
Low-effort Deployment
As I've written in the past, Haskell programs can be very simple to deploy (git
push!). Haskell programs compile to a runnable binary, which thanks to stack, can always be built reliably (i.e. no dependency hell).
Short-comings
mapalgebra is just that - a library for Map Algebra. It will not cook you dinner nor do your taxes. If you need a more fully featured GIS suite, please consider GeoTrellis.
There are benefits to having a focus, of course. Even so, here are some reasons why you might want to avoid mapalgebra until future versions.
Projections aren't read at IO time
With v0.1, projection information isn't yet read out of imagery and enforced statically like size is. This means that using the p parameter is a "best practice". If you mark an image as being WebMercator and it's actually LatLng... well, best of luck.
How could this be fixed? Tiff metadata reading is a planned feature for Massiv, the library upon which mapalgebra is built. Once that is complete, then Projection can be enforced like size.
Imagery size must be known ahead of time
This is by design, but I could see there being claims that it's inconvenient for live systems.
How could this be fixed? There are two paths I can see:
- Double down. Make a judgement that imagery size is a data sanitation problem, and that all imagery of differing size should be transformed before being fed through
mapalgebra.
- Provide a function like:
which, when annotated with the projection and dimensions you want will automatically reproject and up/downsample if necessary when imagery is read. That way, the "data sanitation gate" is held at the IO boundary, and all of your Map Algebra will be rigourous.
Incomplete NoData handling
Say you have this image:

Lots of NoData here, which is pretty common for Landsat imagery. What happens if we naively run a Focal Operation over it? Currently, Focal Ops only support a 3x3 square neighbourhood, so not much would go wrong: our data/nodata border pixels might accrue artifacts. This would be especially pronounced with an Int cell type and -2^63 as the NoData value.
One way to handle the NoData in a typesafe way is via Maybe:
import Data.Monoid (Sum(..))
-- | `Maybe` has a `Monoid` instance, which by default ignores
-- any `Nothing` that are added to it.
-- `fmonoid` is used to smash the neighbourhood together.
nodatafsum :: Raster S p r c Word8 -> Raster DW p r c 512 Word8
nodatafsum =
fmap (maybe 0 getSum) . fmonoid . strict B . fmap check . lazy
where check 0 = Nothing
check n = Just $ Sum nThe problem is that due to the strict B, a boxed vector is allocated which slows this operation down quite a bit. So, which'll it be? Correctness or speed?
How could this be fixed? We have a few options:
- Give up and say "that's the cost of type safety".
- Declare that NoData is also a data sanitization problem and that all imagery should have its NoData interpolated or removed before being ran through
mapalgebra. - Give
Maybean instance ofStorablesomehow, so thatstrict Scan be used instead. - Investigate Unboxed Sums more deeply.
Limited Histogram support
As of v0.1.1, Histograms (summaries of value counts in a Raster) can only be calculated for Rasters that contain Word8 values. The function that does this - histogram - is extremely fast, but to be stuck with Word8 is too limiting for real imagery.
How could this be fixed? Histograms can be manipulated to give better spreads over the colours, but the most valuable way to do that is context dependent. I need to do more research before implementing the general case for bigger Int types, floating types, and ADTs.
No reprojection support
There is a Projection typeclass, but instances have not been written for the various types.
How could this be fixed? Do some research and write them, lazy bones.
Slow faspect and fgradient
fvolume, fupstream, and fdownstream are quite fast due to some math tricks. Their angle-oriented siblings, however, had no such shortcuts that I knew of. I call out to another library, hmatrix, to handle the linear algebra ops described in the module documentation, and something about this undoes the usual efficiency of windowed Rasters.
How could this be fixed? Are their better approaches to faspect and fgradient? Maybe I should be using a different Linear Algebra library.
No extended neighbourhood for Focal Ops
This is a non-trivial thing to leave out, but honestly I didn't have the resources to include this in an initial version of the library.
If you need extended or non-square neighbourhoods, please consider GeoTrellis which has a variety.
How could this be fixed? Perhaps for each focal op, say fmean, I could provide a variant fmeanWith that takes an arbitrary stencil. I'd also have to provide some stencil making functions, so that it would be easy to, for instance, generate a 10x10 square on a whim.
No true Multiband support
mapalgebra and Massiv rely on JuicyPixels for image IO. At present, it can only read TIFFs in RGBA mode (or simpler). True multibanded imagery, like that from Landsat, just can't be read.
How could this be fixed? We already have the RGBARaster wrapper type, but that's not enough. I need to either:
- Tell JuicyPixels about my needs (or submit a patch).
- Write my own library for specifically reading multiband geotiffs.
Either way, mapalgebra takes the stance that multiband imagery, as a special data type, doesn't exist. A multiband image is just a collection of singleband images, which are each just a Raster.
Potentially long compile times
In order to be performant, mapalgebra relies on -O2 and a lot of inlining. Depending on the amount of calls to its functions, this can really slow down compilation of your code.
How could this be fixed? That's life, I'm afraid. When testing, make sure to compile with stack build --fast so that all optimizations are skipped. It really makes a difference.
Why not GPU?
If going single-machine, why not do it "right" and use a giant GPU instead? I can't find a rebuttle for that, other than that CPUs seem more readily available. This is somewhat of an existential issue for mapalgebra - for it to have value we'd need to agree that CPU-based Raster processing is useful. Is it? I hope so.
What about Rasterio (Python)?
Rasterio is a Python library for reading and writing GeoTIFFs, and performing basic Local Operations. It aims for improvement in usability over the Python binding provided by GDAL.
Philosophy and Strengths
Rasterio's solution to the Raster processing problem? Use C to go fast.
GDAL and Numpy
Rasterio uses GDAL, a well-known C library, for its IO. After an image has been read, users are given NumPy arrays to work with. Rasterio thus directly benefits from the speed of NumPy's operations, which are all written in C at the lowest level.
Both GDAL and NumPy are well-established projects with many developers behind them.
Mindshare
Python is huge. It's installed by default on many modern systems and has a low learning curve. This, and the advent of NumPy/SciPy, have made it a darling of the Data Science world.
This is good from an employability standpoint - what dev doesn't know / can't learn Python?
This is also good from a research standpoint - a supervisor can feel confident in assigning "Learn Python" to a student as a preliminary research task.
Low-effort Deployment
Since all Python programs are just scripts, making sure GDAL is properly installed on the host system is about the only problem you might have.
Short-comings
Dynamic Language
Python has neither explicit types nor a compiler. This might be fine for prototyping, but for large or long-running projects, this approach can accrue technical debt. Beyond a certain code size, proposed changes become paralyzing: "What will the effect of me changing these function arguments be?" You won't know until run-time.
Given the nature of Data Science, one would expect a little more rigour. To compare briefly to mapalgebra, Rasterio will not shield you from mismatches in Projection, Raster size, or pixel data type. Python also brings with it all the pitfalls of being able to freely mix effectful (i.e. IO) and non-effectful code.
How could this be fixed? You may want to consider Coconut, a dialect of Python with first-class support for Functional Programming and Static Types. It compiles to regular Python, so you shouldn't lose anything.
No Focal Operations
As far as I could find, Focal Operations (or Zonal, for that matter) are not provided by default by either Rasterio or NumPy. You may be able to replicate Focal Mean with some Convolution, but something more involved like Focal Gradient won't come prepackaged.
How could this be fixed? If you need Focal Operations, you will have to write them yourself or look elsewhere.
What about GeoTrellis (Scala)?
GeoTrellis is a feature-rich GIS library suite for Scala (docs). It can process raster, vector (geometric), vector tile, and point-cloud data, and has integration with many popular storage systems, like S3 and Cassandra.
Disclaimer: I used to work for the team that created and maintains GeoTrellis. Were it not for their wisdom and support, I would not be where I am today. I thank them and all of my former coworkers for everything they taught me.
Anything written here is done so with the utmost respect for my former colleagues and their continuing effort.
Philosophy and Strengths
GeoTrellis' answer to the Raster processing problem? Distribution.
Scalability
My data is big... and I mean /big/.
Gigabytes? Terabytes? No problem. GeoTrellis is built on Apache Spark, and regularly combines large imagery into colour-corrected tile layers in jobs that span scores of machines. The imagery it can handle and the processing network can both be arbitrarily big.
IO Flexibility
GeoTrellis can read GeoTIFFs from anywhere in any band count, and provides data structures for further processing.
With the geotrellis-spark package, it's common to create ETL pipelines that process imagery, pyramid resulting tiles, and output a range of zoom levels for later use in a Tile Server.
With the upcoming 2.0.0 release, GeoTrellis also provides an implementation of Cloud-Optimized GeoTiff Layers. These offer a significant performance improvement for IO, are better suited for storage on HDFS/S3 than the old format, and allow GeoTrellis Layers to be viewable in QGIS.
Feature Richness
GeoTrellis is a suite of libraries, but the geotrellis-raster package alone boasts a number of ready-to-use GIS operations, including:
- Cost Distance
- Hydrology ops
- Colour and ASCII rendering
- Map Algebra
- Rasterization (i.e. Vector -> Raster conversion)
- Reprojection and Resampling
- Raster Stitching
- Viewshed
For Geometric data, GeoTrellis has integrations for the well-known Java Topology Suite, GeoMesa, and GeoWave. (Everyone loves the Geo puns, don't they?)
The point is, if you've got data, GeoTrellis knows how to read it and process it.
Short-comings
When you want to go fast on the JVM, it makes certain demands of you. These demands, along with the sheer size and scope of GeoTrellis, have created some issues over the years.
Opaque Tile Types
Unlike the Raster u p r c a type from mapalgebra, most GeoTrellis Raster operations yield a non-generic Tile type. In order to handle different underlying types, Tile forms a very large OO inheritance hierarchy with a lot of duplicated code.
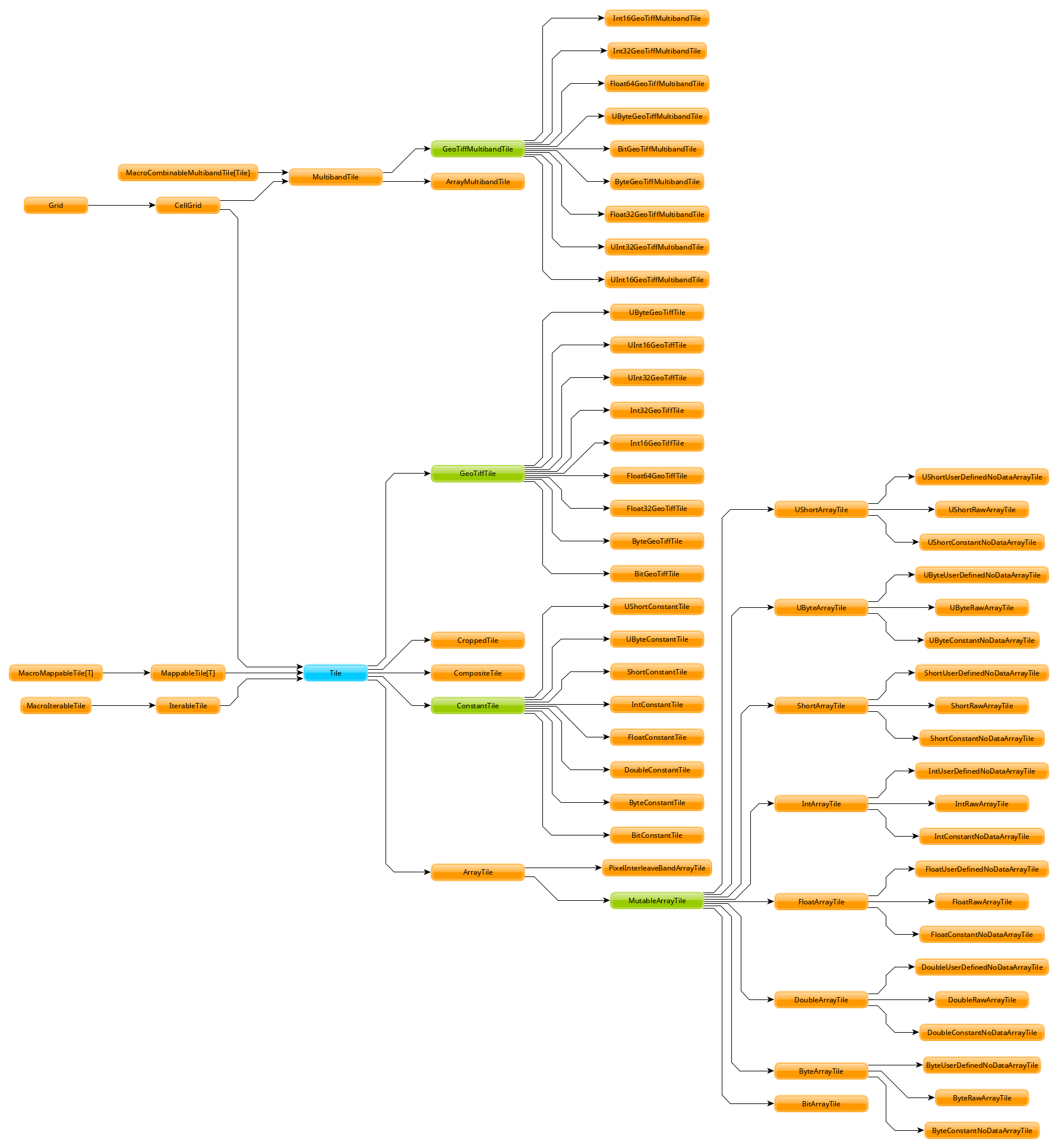{kind=link}
Speed is the motivation. If you want to go fast on the JVM, you need Arrays, Ints, and Doubles. One consequence of this is the foo / fooDouble pattern, seen here with ArrayTile.map:
def map(f: Int => Int): Tile = {
val output = ArrayTile.alloc(cellType, cols, rows)
var i = 0
val len = size
while (i < len) {
output(i) = f(apply(i))
i += 1
}
output
}
def mapDouble(f: Double => Double): Tile = {
val len = size
val tile = ArrayTile.alloc(cellType, cols, rows)
var i = 0
while (i < len) {
tile.updateDouble(i, f(applyDouble(i)))
i += 1
}
tile
}Another is that all potential underlying types (say, ushort) need to be simulated with Int and Double. This creates a lot of code duplication and a large surface area for bugs.
How could this be fixed? A generic Tile[A] has long been sought. Since the JVM aggressively boxes primitives if you aren't careful, naive case class based solutions don't work. Generic Map Algebra seems possible with typeclasses and raw Array, but the latest news on the wind is that GeoTrellis will look into ND4J Arrays instead to underpin Tile.
Mixed Projections and Raster Sizes
A common problem:
A: Something's not right with my results... I've poured over my code but can't figure it out.
B: Are all your projections matching?
A: ...crap.
It's frustrating when a one-line oversight like this wastes hours of ingest time. Since Tile is opaque, the compiler can't protect us from errors like this. The result is a need to keep a lot of tiny details in your head while coding.
How could this be fixed? Either:
- A generic
Tiletype that exposes aCRSin the type signature, or; - Run-time checks whenever operations between two Rasters are performed, to make sure the operation is legal. This would mean a lot of boilerplate and opportunity for bugs.
Lack of Op Fusion
Binary Local Operations like tile1 + tile2 allocate a new Array. Further, for each Array index in either Tile, a NoData comparison is made.
Let's consider EVI again:
/* Enhanced Vegetation Index */
def evi(nir: Tile, red: Tile, blue: Tile): Tile =
((nir - red) / (nir + (red * 6) - (blue * 7.5) + 1)) * 2.5There are 8 operators here, which means many repeated iterations over the Arrays and many redundant NoData checks. This does bring a performance cost.
How could this be fixed? Either by implementing a kind of LazyTile type which has been discussed in the past, or by improving the performance of current operations to the point where redundant allocations don't matter as much.
API Discoverability
GeoTrellis utilizes around 20 actual data types (Tile, Polygon, etc.). Despite this, its scaladocs present users with 2,223 top-level symbols. Around 500 of these are method-injection boilerplate classes which permit calls like the following:
import geotrellis.raster.mapalgebra.focal._
// Given...
val tile: Tile = ???
val n: Neighbourhood = Square(1)
// Instead of this, which looks like class instantiation...
val averaged1: Tile = Mean(tile, n)
// ...we can do this. Much more idiomatic!
val averaged2: Tile = tile.focalMean(n)For modularity reasons .focalMean isn't defined directly within the Tile class. This is good because it keeps the Tile class clean. What isn't good is the resulting boilerplate: the 500 extra top-level symbols which a user doesn't need to see but is shown anyway.
Another downside is that .focalMean doesn't appear in Tile's scaladocs entry. The question "what can I do to a Tile? " is not easy to answer. This situation comes up often too:
I want to turn a ~Tile~ into a ~Foo~. What do I need to import and what injected method do I need to call for that?
The pursuit of that answer has burnt a lot of user time over the years. The worst case scenario is when they need to ask us directly for help manipulating core data structures. Something is wrong when a library's basic functionality is not self-explanitory.
How could this be fixed? A few things would reduce top-level symbol count and make GeoTrellis easier to learn:
- Aggressive use of
privateto hide details which aren't important for users to see. geotrellis.foo.bar.internalmodules which hide non-user-facing types and machinery.- Removal of "Verb Classes".
- Using simulacrum-based typeclasses instead of ad-hoc method injection.
- Building Scaladocs without symbols from docs code samples test suites included.
Heavy Call Indirection and Method Overloading
Assume we had started with:
val t1: Tile =
IntArrayTile.empty(512, 512).map { (c, r, _) => c * r }
val t2: Tile =
IntArrayTile.empty(512, 512).map { (c, r, _) => c * r + 1 }what does it take to perform a Local Sum?
More than you might think. Tile does not have + directly defined on it. Instead:
Tileis implicitely wrapped withclass withTileMethods. (geotrellis/raster/package.scala)- Along with 25 other traits,
withTileMethodsextendsLocalMethods. - Along with 19 other traits,
LocalMethodsextendsAddMethods. (geotrellis/raster/mapalgebra/local/LocalMethods.scala) - Injected method
+redirects tolocalAdd. (geotrellis/raster/mapalgebra/local/Add.scala#L57) localAddlooks like it's instantiating an instance of anAddclass:
But it's not - this is implicitely a call to Add.apply. Does Add have an .apply method?
object Add extends LocalTileBinaryOp {
def combine(z1: Int, z2: Int) = ...
def combine(z1: Double, z2: Double) = ...
}- No,
.applyis actually defined inLocalTileBinaryOp, of which there are 6 overloads. (geotrellis/raster/mapalgebra/local/LocalTileBinaryOp.scala#L55) - This
.applycallsTile.dualCombine. - We have
Inttiles, so this redirects tocombine. (geotrellis/raster/Tile.scala#L100) combineis abstract, so we check which subclass it's implemented in.- We started with
IntArrayTile, butcombineisn't defined there. MaybeMutableArrayTile, its parent? - Not there either. Maybe its parent,
ArrayTile? - Found it.
combineis overloaded though, and redirects to another variation. (geotrellis/raster/ArrayTile.scala#L224) - A new
Arrayis allocated, and the givenfis applied to each index. (geotrellis/raster/ArrayTile.scala#210) - Which
fis that? It's what was given todualCombine, namelyLocalTileBinaryOp.combine. - This
combineis abstract. The actual code is back inAdd.scala(shown above), and performsIntaddition with some NoData checking. - Finally, a new
ArrayTilemasked asTileis returned.
This level of indirection is frequent throughout the library. It:
- worsens performance
- increases development costs by making it hard to find where anything is actually defined
- makes the true source of bugs difficult to locate
- gives users choice paralysis (e.g. "which method is the right one?")
How can this be fixed? A generic Tile type and more use of typeclasses would decrease boilerplate and indirection. A removal of "Verb Classes" like Add and a reduced reliance on OO-style hierarchies-for-the-sake-of-hierarchies would also help.
Verbosity, Complexity, and Maintenance Cost
It has been my experience that Haskell code is usually much shorter than Scala for equivalent functionality. mapalgebra has around 600 lines of code (not counting comments). The total line count of all modules from GeoTrellis that implement the "same" functionality is around 6,000.
Scala has a certain aspect to it that makes it easy to accidentally write verbose code. As demonstrated in the Indirection section above, it's also easy to write oneself into complexity. If GeoTrellis would be your / your company's first foray into Scala, consider that development and maintenance of your project may take more people than necessary.
How could this be fixed? I don't know that it can be. Scala would have to be a different language altogether.
High-effort Deployment
GeoTrellis assumes the use of Spark for many of its features. However, there are a number of things one has to keep in mind when deploying a Spark-based GeoTrellis program.
Level: Critical. Omitting one of these will almost certainly cause the Spark job to fail.
- Is the JVM instance in production assigned enough RAM?
- If running in a Docker container, do the container's memory settings conflict with the JVM's?
- Have I configured executor memory settings to the exact value that will prevent them from either dying at runtime or under-utilizing resources?
- Did I request enough executor machines to be able to store the collective memory of the job?
- Is the version of Spark I'm testing with the same as the version available on AWS?
- Is AWS running the same version of Java that I need?
- Are my AWS credentials fed through correctly to access S3?
- Are the exact Spark, Hadoop, and GeoTrellis dependencies marked as
... % "provided"inbuild.sbtso that there aren't conflicts with AWS at runtime? - Did I remember to upload the most recent version of my assembled code to S3 for Spark?
- Did I ensure I didn't assemble "stale" code? (i.e. "Don't trust
sbt clean. ") - Am I using too few
RDDpartitions?
Level: Annoying. Omitting these will increase your AWS bill.
- Have I configured things correctly such that Exception logs are available when I need to find them?
- Am I using AWS "spot instances" so that my Spark job doesn't cost too much?
- Am I using
RDDcaching in the exact places that will prevent redundant work? - Have I made sure not to force
RDDexecution before I should be (with.count, etc.)? - Am I using too many
RDDpartitions?
If you'd rather avoid keeping track of these details, then perhaps you should seek an alternative to Spark. Are you sure you need it?
Potential Overkill
Spark is popular, and everyone wants to be doing "big data". Chances are, though, that your data isn't really that big. In which case, the Spark integration for GeoTrellis is not necessary for you - you may be fine with single-machine raster processing. If single-machine, navigating basic use of GeoTrellis and the effort of deploying a Spark program may not be worth it. Consider also that both Rasterio and mapalgebra have better single-machine performance.
If you just want to do some simple Map Algebra on reasonably sized images, GeoTrellis is probably overkill. You might be interested instead in Raster Foundry, a web app for working with imagery visually.
Comparisons
Code Samples
These are by no means comprehensive, but do give a feel for each library.
Read an Image
Reading a 512x512 singleband image.
mapalgebra:
import Geography.MapAlgebra
singleband :: IO (Either String (Raster S p 512 512 Word8))
singleband = fromGray "path/to/image.tif"Rasterio:
import rasterio
def work():
with rasterio.open("path/to/image.tif") as dst:
singleband = dst.read(1)
# Do some work on my_raster.
# File is automatically closed afterward.GeoTrellis:
import geotrellis.raster.Tile
import geotrellis.raster.io.geotiff.SinglebandGeoTiff
def singleband: Tile =
SinglebandGeoTiff("path/to/image.tif").tileWrite an Image
Write some given 512x512 Raster.
mapalgebra:
import Geography.MapAlgebra
-- | PRO: Works on Rasters of any projection, size, and pixel value.
-- CON: Drops GeoTIFF metadata (none was read to begin with).
writeItGray :: Elevator a => Raster D p r c a -> IO ()
writeItGray =
writeImageAuto "output/path/img.tif" . _array . strict S . grayscaleRasterio:
import rasterio
# PRO: Mimics the usual Python syntax for writing files.
# CON: Fairly verbose. Why can't most of the info passed to `open` be
# determined automatically from the `tile` passed to `write`?
def writeItGray(tile):
with rasterio.open("output/path/image.tif", "w",
driver="GTiff",
height=tile.shape[0], width=tile.shape[1],
count=1, dtype=tile.dtype) as dst:
dst.write(tile, 1)GeoTrellis:
import geotrellis.raster.io.geotiff.SinglebandGeoTiff
/** PROs:
* - Simple, one method call.
* - Maintains `Extent` and `CRS` information in GeoTIFF metadata.
* CONs:
* - Pixel type isn't transparent.
* Is this writing bytes? Ints? Doubles?
* - Returns `Unit` instead of safer `IO[Unit]`.
*/
def writeItGray(tile: SinglebandGeoTiff): Unit =
tile.write("output/path/image.tif")Colour an Image
mapalgebra:
import Geography.MapAlgebra
-- | Colouring is just Local Classification.
colourIt :: Raster S p r c Word8 -> Raster S p r c (Pixel RGBA Word8)
colourIt r = strict S . classify invisible cm $ lazy r
where cm = spectrum . breaks $ histogram rRasterio:
GeoTrellis:
import geotrellis.raster.Tile
import geotrellis.raster.render.{ColorMap, ColorRamp, ColorRamps, Png}
import geotrellis.raster.histogram.{Histogram, StreamingHistogram}
/** Renders straight to an encoded `Png` - there is no "coloured Raster"
* stage. It was a bit tricky to discover the precise things that need
* to be called in order to create a `ColorMap`.
*/
def colourIt(tile: Tile): Png = {
val cr: ColorRamp = ColorRamps.Viridis
val ht: Histogram[Double] = StreamingHistogram.fromTile(tile)
val cm: ColorMap = ColorMap.fromQuantileBreaks(ht, cr)
tile.renderPng(cm)
}Enhanced Vegetation Index (EVI)
mapalgebra:
import Geography.MapAlgebra
evi :: Raster D p r c Double
-> Raster D p r c Double
-> Raster D p r c Double
-> Raster D p r c Double
evi nir red blue = 2.5 * (numer / denom)
where numer = nir - red
denom = nir + (6 * red) - (7.5 * blue) + 1Rasterio:
GeoTrellis:
import geotrellis.raster._
def evi(nir: Tile, red: Tile, blue: Tile): Tile =
((nir - red) / (nir + (red * 6) - (blue * 7.5) + 1)) * 2.5Benchmarks
These benchmarks were performed on a 2016 Lenovo X1 Carbon with 4 CPUs.
| Language | Version |
|---|---|
| Haskell | GHC 8.4.1 w/ LLVM 5.0 |
| Scala | 2.11.12 (JVM) |
| Python | CPython 3.6.5 |
All times are in milliseconds, shorter bars are better. Unless otherwise stated, all operations are over a 512x512 image.
Local Operations
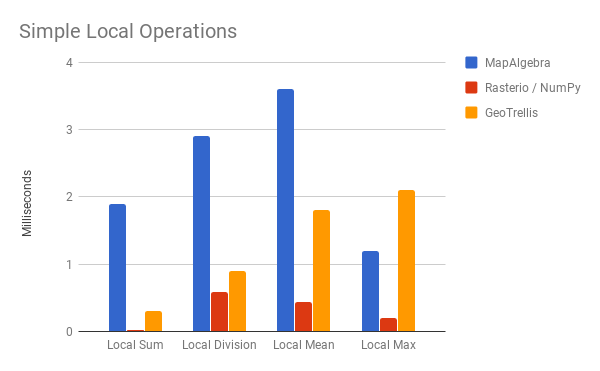
These are four local ops which could be written for Python. Much more and NumPy has no way to approach them (say, Local Variance). mapalgebra and GeoTrellis both host a greater variety of operations.
Local Sum for Rasterio looks very fast - I suspect some serious optimizations are occuring under the hood. By comparison, mapalgebra looks quite slow. Let's keep in mind however that this is a one-off measurement which doesn't demonstrate op fusion. Further, the cost of allocating new memory is about 1ms here, a cost which only needs to be paid once per fused op chain.
EVI demonstrates this better (watch the yellow bar):
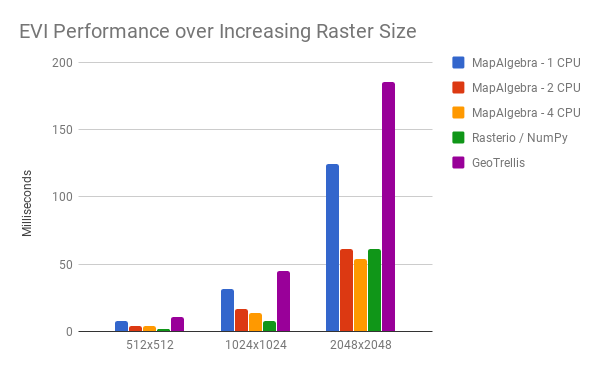
Recall that EVI has 8 chained numerical operations. As CPU count and Raster size increase, mapalgebra pulls ahead even of the C code that powers NumPy. We can expect this to improve further as GHC develops SIMD support.
Op fusion pays off again as we perform EVI, colour a Raster, and encode it as a .png:
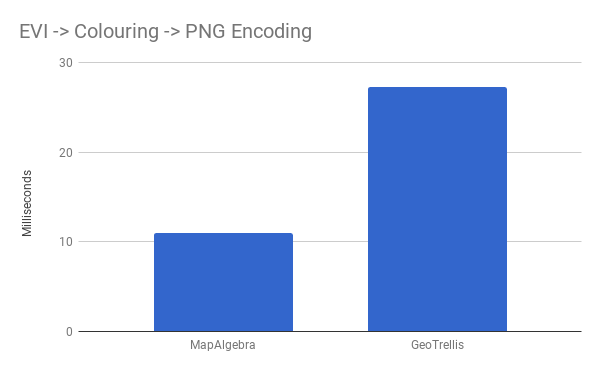
Rasterio was left out here, as it has no support for encoding PNGs outside of the IO process.
Focal Operations
mapalgebra defines more Focal Ops than GeoTrellis, but we measure the common ones here. Rasterio is left out completely, as it has no support for these.
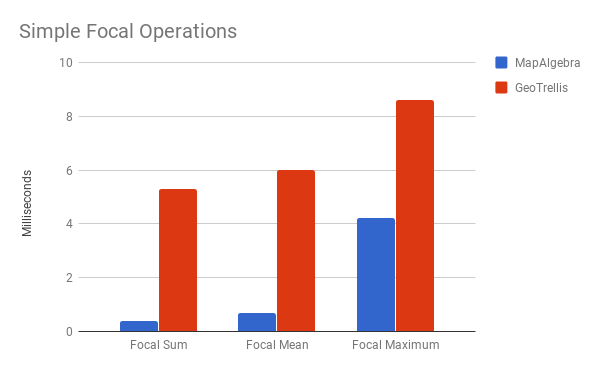
This is the strength of Windowed Rasters, parallelism, and LLVM optimizations. That said, remember those slow Surficial ops I mentioned?
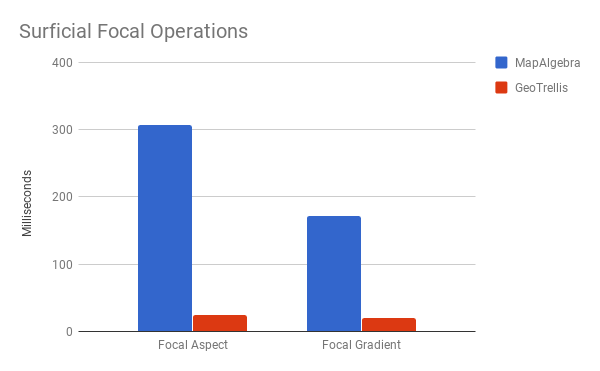
Yikes. I really need to figure out what's killing the optimizations.
Final Thoughts
If you have an existing Python code base or want to integrate with other Python libraries, use Rasterio. It has consistently good performance, for an albeit small set of possible operations.
If you need a fully-featured GIS suite, or your Raster processing work would provably benefit from distributed computing, use GeoTrellis.
If you're a Haskeller interested in GIS, a GISer interested in Haskell, or just want fast and safe single-machine Raster processing code, use mapalgebra.